Modern object classes and methods for handling data.frame like structures
are provided by the dplyr and data.table packages. The following gives a
short introduction to the usage and functionalities of the dplyr package.
More detailed tutorials on this topic can be found here:
- dplyr: A Grammar of Data Manipulation
- Introduction to
dplyr - Tutorial on
dplyr - Cheatsheet for Joins from Jenny Bryan
- Tibbles
- Intro to
data.tablepackage - Big data with
dplyranddata.table - Fast lookups with
dplyranddata.table
Installation
The dplyr environment has evolved into an ecosystem of packages. To simplify
package management, one can install and load the entire collection via the
tidyverse package. For more details on tidyverse see
here.
install.packages("tidyverse")
Construct a data frame (tibble)
library(tidyverse)
as_data_frame(iris) # coerce data.frame to data frame tbl
## # A tibble: 150 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <fctr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ... with 140 more rows
Alternative functions producing the same result include as_tibble and tbl_df:
as_tibble(iris) # newer function provided by tibble package
tbl_df(iris) # this alternative exists for historical reasons
Reading and writing tabular files
While the base R read/write utilities can be used for data frames, best time
performance with the least amount of typing is achieved with the export/import
functions from the readr package. For very large files the fread function from
the data.table package achieves the best time performance.
Import with readr
Import functions provided by readr include:
read_csv(): comma separated (CSV) filesread_tsv(): tab separated filesread_delim(): general delimited filesread_fwf(): fixed width filesread_table(): tabular files where colums are separated by white-space.read_log(): web log files
Create a sample tab delimited file for import
write_tsv(iris, "iris.txt") # Creates sample file
Import with read_tsv
iris_df <- read_tsv("iris.txt") # Import with read_tbv from readr package
iris_df
## # A tibble: 150 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ... with 140 more rows
To import Google Sheets directly into R, see here.
Fast table import with fread
The fread function from the data.table package provides the best time performance for reading large
tabular files into R.
library(data.table)
iris_df <- as_data_frame(fread("iris.txt")) # Import with fread and conversion to tibble
iris_df
## # A tibble: 150 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ... with 140 more rows
Note: to ignore lines starting with comment signs, one can pass on to fread a shell
command for preprocessing the file. The following example illustrates this option.
fread("grep -v '^#' iris.txt")
Export with readr
Export function provided by readr inlcude
write_delim(): general delimited fileswrite_csv(): comma separated (CSV) fileswrite_excel_csv(): excel style CSV fileswrite_tsv(): tab separated files
For instance, the write_tsv function writes a data frame to a tab delimited file with much nicer
default settings than the base R write.table function.
write_tsv(iris_df, "iris.txt")
Column and row binds
The equivalents to base R’s rbind and cbind are bind_rows and bind_cols, respectively.
bind_cols(iris_df, iris_df)
## # A tibble: 150 <U+00D7> 10
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species Sepal.Length Sepal.Width Petal.Length
## <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl>
## 1 5.1 3.5 1.4 0.2 setosa 5.1 3.5 1.4
## 2 4.9 3.0 1.4 0.2 setosa 4.9 3.0 1.4
## 3 4.7 3.2 1.3 0.2 setosa 4.7 3.2 1.3
## 4 4.6 3.1 1.5 0.2 setosa 4.6 3.1 1.5
## 5 5.0 3.6 1.4 0.2 setosa 5.0 3.6 1.4
## 6 5.4 3.9 1.7 0.4 setosa 5.4 3.9 1.7
## 7 4.6 3.4 1.4 0.3 setosa 4.6 3.4 1.4
## 8 5.0 3.4 1.5 0.2 setosa 5.0 3.4 1.5
## 9 4.4 2.9 1.4 0.2 setosa 4.4 2.9 1.4
## 10 4.9 3.1 1.5 0.1 setosa 4.9 3.1 1.5
## # ... with 140 more rows, and 2 more variables: Petal.Width <dbl>, Species <chr>
bind_rows(iris_df, iris_df)
## # A tibble: 300 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ... with 290 more rows
Extract column as vector
The subsetting operators [[ and $can be used to extract from a data frame single columns as vector.
iris_df[[5]][1:12]
## [1] "setosa" "setosa" "setosa" "setosa" "setosa" "setosa" "setosa" "setosa" "setosa" "setosa"
## [11] "setosa" "setosa"
iris_df$Species[1:12]
## [1] "setosa" "setosa" "setosa" "setosa" "setosa" "setosa" "setosa" "setosa" "setosa" "setosa"
## [11] "setosa" "setosa"
Important dplyr functions
filter()andslice()arrange()select()andrename()distinct()mutate()andtransmute()summarise()sample_n()andsample_frac()
Slice and filter functions
Filter function
filter(iris_df, Sepal.Length > 7.5, Species=="virginica")
## # A tibble: 6 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 7.6 3.0 6.6 2.1 virginica
## 2 7.7 3.8 6.7 2.2 virginica
## 3 7.7 2.6 6.9 2.3 virginica
## 4 7.7 2.8 6.7 2.0 virginica
## 5 7.9 3.8 6.4 2.0 virginica
## 6 7.7 3.0 6.1 2.3 virginica
Base R code equivalent
iris_df[iris_df[, "Sepal.Length"] > 7.5 & iris_df[, "Species"]=="virginica", ]
## # A tibble: 6 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 7.6 3.0 6.6 2.1 virginica
## 2 7.7 3.8 6.7 2.2 virginica
## 3 7.7 2.6 6.9 2.3 virginica
## 4 7.7 2.8 6.7 2.0 virginica
## 5 7.9 3.8 6.4 2.0 virginica
## 6 7.7 3.0 6.1 2.3 virginica
Including boolean operators
filter(iris_df, Sepal.Length > 7.5 | Sepal.Length < 5.5, Species=="virginica")
## # A tibble: 7 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 7.6 3.0 6.6 2.1 virginica
## 2 4.9 2.5 4.5 1.7 virginica
## 3 7.7 3.8 6.7 2.2 virginica
## 4 7.7 2.6 6.9 2.3 virginica
## 5 7.7 2.8 6.7 2.0 virginica
## 6 7.9 3.8 6.4 2.0 virginica
## 7 7.7 3.0 6.1 2.3 virginica
Subset rows by position
dplyr approach
slice(iris_df, 1:2)
## # A tibble: 2 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
Base R code equivalent
iris_df[1:2,]
## # A tibble: 2 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
Subset rows by names
Since data frames do not contain row names, row wise subsetting via the [,] operator cannot be used.
However, the corresponding behavior can be achieved by passing to select a row position index
obtained by basic R intersect utilities such as match.
Create a suitable test data frame
df1 <- bind_cols(data_frame(ids1=paste0("g", 1:10)), as_data_frame(matrix(1:40, 10, 4, dimnames=list(1:10, paste0("CA", 1:4)))))
df1
## # A tibble: 10 <U+00D7> 5
## ids1 CA1 CA2 CA3 CA4
## <chr> <int> <int> <int> <int>
## 1 g1 1 11 21 31
## 2 g2 2 12 22 32
## 3 g3 3 13 23 33
## 4 g4 4 14 24 34
## 5 g5 5 15 25 35
## 6 g6 6 16 26 36
## 7 g7 7 17 27 37
## 8 g8 8 18 28 38
## 9 g9 9 19 29 39
## 10 g10 10 20 30 40
dplyr approach
slice(df1, match(c("g10", "g4", "g4"), df1$ids1))
## # A tibble: 3 <U+00D7> 5
## ids1 CA1 CA2 CA3 CA4
## <chr> <int> <int> <int> <int>
## 1 g10 10 20 30 40
## 2 g4 4 14 24 34
## 3 g4 4 14 24 34
Base R equivalent
df1_old <- as.data.frame(df1)
rownames(df1_old) <- df1_old[,1]
df1_old[c("g10", "g4", "g4"),]
## ids1 CA1 CA2 CA3 CA4
## g10 g10 10 20 30 40
## g4 g4 4 14 24 34
## g4.1 g4 4 14 24 34
Sorting with arrange
Row-wise ordering based on specific columns
dplyr approach
arrange(iris_df, Species, Sepal.Length, Sepal.Width)
## # A tibble: 150 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 4.3 3.0 1.1 0.1 setosa
## 2 4.4 2.9 1.4 0.2 setosa
## 3 4.4 3.0 1.3 0.2 setosa
## 4 4.4 3.2 1.3 0.2 setosa
## 5 4.5 2.3 1.3 0.3 setosa
## 6 4.6 3.1 1.5 0.2 setosa
## 7 4.6 3.2 1.4 0.2 setosa
## 8 4.6 3.4 1.4 0.3 setosa
## 9 4.6 3.6 1.0 0.2 setosa
## 10 4.7 3.2 1.3 0.2 setosa
## # ... with 140 more rows
For ordering descendingly use desc() function
arrange(iris_df, desc(Species), Sepal.Length, Sepal.Width)
## # A tibble: 150 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 4.9 2.5 4.5 1.7 virginica
## 2 5.6 2.8 4.9 2.0 virginica
## 3 5.7 2.5 5.0 2.0 virginica
## 4 5.8 2.7 5.1 1.9 virginica
## 5 5.8 2.7 5.1 1.9 virginica
## 6 5.8 2.8 5.1 2.4 virginica
## 7 5.9 3.0 5.1 1.8 virginica
## 8 6.0 2.2 5.0 1.5 virginica
## 9 6.0 3.0 4.8 1.8 virginica
## 10 6.1 2.6 5.6 1.4 virginica
## # ... with 140 more rows
Base R code equivalent
iris_df[order(iris_df$Species, iris_df$Sepal.Length, iris_df$Sepal.Width), ]
## # A tibble: 150 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 4.3 3.0 1.1 0.1 setosa
## 2 4.4 2.9 1.4 0.2 setosa
## 3 4.4 3.0 1.3 0.2 setosa
## 4 4.4 3.2 1.3 0.2 setosa
## 5 4.5 2.3 1.3 0.3 setosa
## 6 4.6 3.1 1.5 0.2 setosa
## 7 4.6 3.2 1.4 0.2 setosa
## 8 4.6 3.4 1.4 0.3 setosa
## 9 4.6 3.6 1.0 0.2 setosa
## 10 4.7 3.2 1.3 0.2 setosa
## # ... with 140 more rows
iris_df[order(iris_df$Species, decreasing=TRUE), ]
## # A tibble: 150 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 6.3 3.3 6.0 2.5 virginica
## 2 5.8 2.7 5.1 1.9 virginica
## 3 7.1 3.0 5.9 2.1 virginica
## 4 6.3 2.9 5.6 1.8 virginica
## 5 6.5 3.0 5.8 2.2 virginica
## 6 7.6 3.0 6.6 2.1 virginica
## 7 4.9 2.5 4.5 1.7 virginica
## 8 7.3 2.9 6.3 1.8 virginica
## 9 6.7 2.5 5.8 1.8 virginica
## 10 7.2 3.6 6.1 2.5 virginica
## # ... with 140 more rows
Select columns with select
Select specific columns
select(iris_df, Species, Petal.Length, Sepal.Length)
## # A tibble: 150 <U+00D7> 3
## Species Petal.Length Sepal.Length
## <chr> <dbl> <dbl>
## 1 setosa 1.4 5.1
## 2 setosa 1.4 4.9
## 3 setosa 1.3 4.7
## 4 setosa 1.5 4.6
## 5 setosa 1.4 5.0
## 6 setosa 1.7 5.4
## 7 setosa 1.4 4.6
## 8 setosa 1.5 5.0
## 9 setosa 1.4 4.4
## 10 setosa 1.5 4.9
## # ... with 140 more rows
Select range of columns by name
select(iris_df, Sepal.Length : Petal.Width)
## # A tibble: 150 <U+00D7> 4
## Sepal.Length Sepal.Width Petal.Length Petal.Width
## <dbl> <dbl> <dbl> <dbl>
## 1 5.1 3.5 1.4 0.2
## 2 4.9 3.0 1.4 0.2
## 3 4.7 3.2 1.3 0.2
## 4 4.6 3.1 1.5 0.2
## 5 5.0 3.6 1.4 0.2
## 6 5.4 3.9 1.7 0.4
## 7 4.6 3.4 1.4 0.3
## 8 5.0 3.4 1.5 0.2
## 9 4.4 2.9 1.4 0.2
## 10 4.9 3.1 1.5 0.1
## # ... with 140 more rows
Drop specific columns (here range)
select(iris_df, -(Sepal.Length : Petal.Width))
## # A tibble: 150 <U+00D7> 1
## Species
## <chr>
## 1 setosa
## 2 setosa
## 3 setosa
## 4 setosa
## 5 setosa
## 6 setosa
## 7 setosa
## 8 setosa
## 9 setosa
## 10 setosa
## # ... with 140 more rows
Renaming columns with rename
dplyr approach
rename(iris_df, new_col_name = Species)
## # A tibble: 150 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width new_col_name
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ... with 140 more rows
Base R code approach
colnames(iris_df)[colnames(iris_df)=="Species"] <- "new_col_names"
Obtain unique rows with distinct
dplyr approach
distinct(iris_df, Species, .keep_all=TRUE)
## # A tibble: 3 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 7.0 3.2 4.7 1.4 versicolor
## 3 6.3 3.3 6.0 2.5 virginica
Base R code approach
iris_df[!duplicated(iris_df$Species),]
## # A tibble: 3 <U+00D7> 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 7.0 3.2 4.7 1.4 versicolor
## 3 6.3 3.3 6.0 2.5 virginica
Add columns
mutate
The mutate function allows to append columns to existing ones.
mutate(iris_df, Ratio = Sepal.Length / Sepal.Width, Sum = Sepal.Length + Sepal.Width)
## # A tibble: 150 <U+00D7> 7
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species Ratio Sum
## <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 5.1 3.5 1.4 0.2 setosa 1.457143 8.6
## 2 4.9 3.0 1.4 0.2 setosa 1.633333 7.9
## 3 4.7 3.2 1.3 0.2 setosa 1.468750 7.9
## 4 4.6 3.1 1.5 0.2 setosa 1.483871 7.7
## 5 5.0 3.6 1.4 0.2 setosa 1.388889 8.6
## 6 5.4 3.9 1.7 0.4 setosa 1.384615 9.3
## 7 4.6 3.4 1.4 0.3 setosa 1.352941 8.0
## 8 5.0 3.4 1.5 0.2 setosa 1.470588 8.4
## 9 4.4 2.9 1.4 0.2 setosa 1.517241 7.3
## 10 4.9 3.1 1.5 0.1 setosa 1.580645 8.0
## # ... with 140 more rows
transmute
The transmute function does the same as mutate but drops existing columns
transmute(iris_df, Ratio = Sepal.Length / Sepal.Width, Sum = Sepal.Length + Sepal.Width)
## # A tibble: 150 <U+00D7> 2
## Ratio Sum
## <dbl> <dbl>
## 1 1.457143 8.6
## 2 1.633333 7.9
## 3 1.468750 7.9
## 4 1.483871 7.7
## 5 1.388889 8.6
## 6 1.384615 9.3
## 7 1.352941 8.0
## 8 1.470588 8.4
## 9 1.517241 7.3
## 10 1.580645 8.0
## # ... with 140 more rows
bind_cols
The bind_cols function is the equivalent of cbind in base R. To add rows, use the corresponding
bind_rows function.
bind_cols(iris_df, iris_df)
## # A tibble: 150 <U+00D7> 10
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species Sepal.Length Sepal.Width Petal.Length
## <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl>
## 1 5.1 3.5 1.4 0.2 setosa 5.1 3.5 1.4
## 2 4.9 3.0 1.4 0.2 setosa 4.9 3.0 1.4
## 3 4.7 3.2 1.3 0.2 setosa 4.7 3.2 1.3
## 4 4.6 3.1 1.5 0.2 setosa 4.6 3.1 1.5
## 5 5.0 3.6 1.4 0.2 setosa 5.0 3.6 1.4
## 6 5.4 3.9 1.7 0.4 setosa 5.4 3.9 1.7
## 7 4.6 3.4 1.4 0.3 setosa 4.6 3.4 1.4
## 8 5.0 3.4 1.5 0.2 setosa 5.0 3.4 1.5
## 9 4.4 2.9 1.4 0.2 setosa 4.4 2.9 1.4
## 10 4.9 3.1 1.5 0.1 setosa 4.9 3.1 1.5
## # ... with 140 more rows, and 2 more variables: Petal.Width <dbl>, Species <chr>
Summarize data
Summary calculation on single column
summarize(iris_df, mean(Petal.Length))
## # A tibble: 1 <U+00D7> 1
## `mean(Petal.Length)`
## <dbl>
## 1 3.758
Summary calculation on many columns
summarize_all(iris_df[,1:4], mean)
## # A tibble: 1 <U+00D7> 4
## Sepal.Length Sepal.Width Petal.Length Petal.Width
## <dbl> <dbl> <dbl> <dbl>
## 1 5.843333 3.057333 3.758 1.199333
Summarize by grouping column
summarize(group_by(iris_df, Species), mean(Petal.Length))
## # A tibble: 3 <U+00D7> 2
## Species `mean(Petal.Length)`
## <chr> <dbl>
## 1 setosa 1.462
## 2 versicolor 4.260
## 3 virginica 5.552
Aggregate summaries
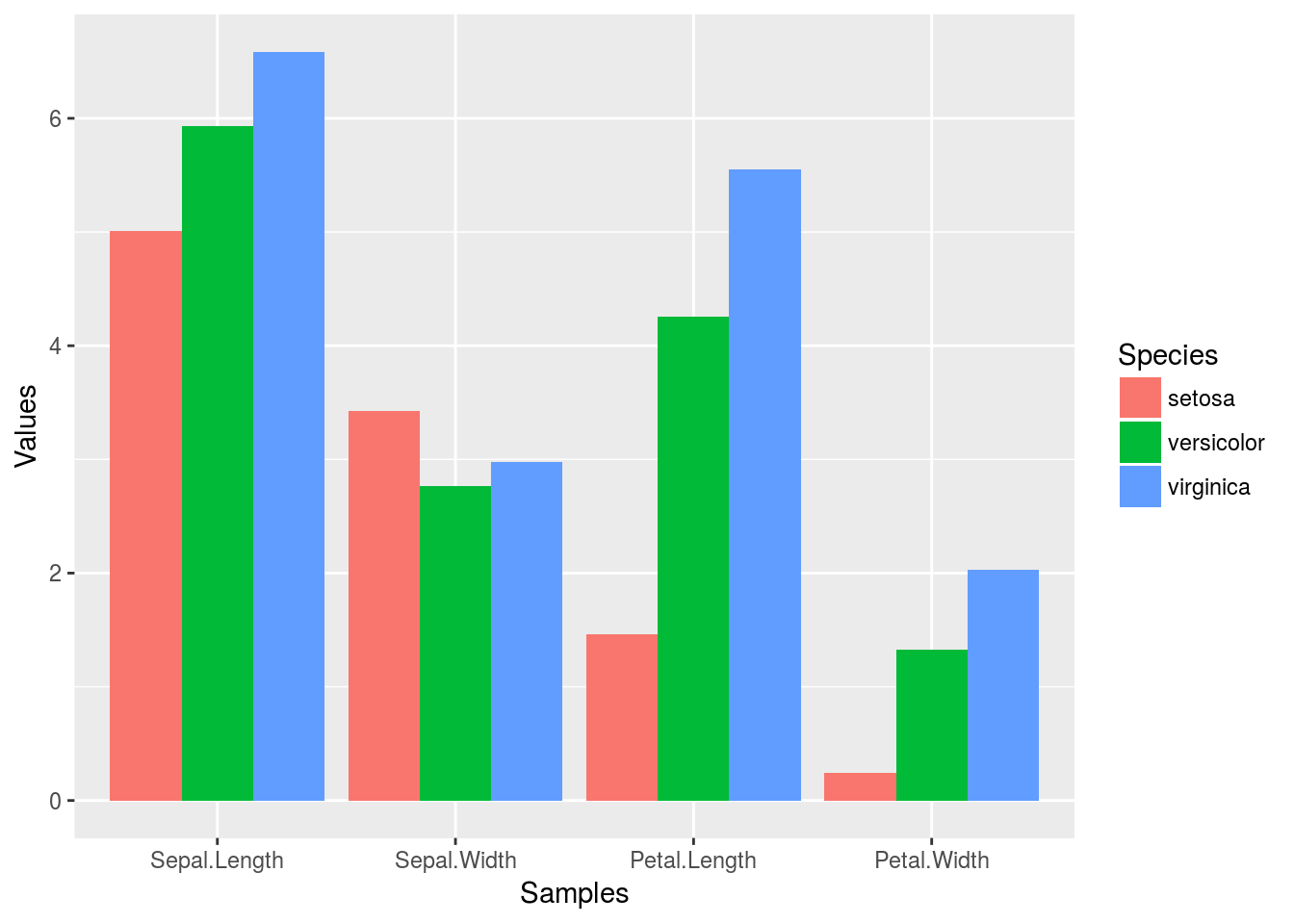
summarize_all(group_by(iris_df, Species), mean)
## # A tibble: 3 <U+00D7> 5
## Species Sepal.Length Sepal.Width Petal.Length Petal.Width
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 setosa 5.006 3.428 1.462 0.246
## 2 versicolor 5.936 2.770 4.260 1.326
## 3 virginica 6.588 2.974 5.552 2.026
Note: group_by does the looping for the user similar to aggregate or tapply.
Merging data frames
The dplyr package provides several join functions for merging data frames by a common key column
similar to the merge function in base R. These *_join functions include:
inner_join(): returns join only for rows matching among bothdata tablesfull_join(): returns join for all (matching and non-matching) rows of twodata tablesleft_join(): returns join for all rows in firstdata tableright_join(): returns join for all rows in seconddata tableanti_join(): returns for firstdata tableonly those rows that have no match in the second one
Sample data frames to illustrate *.join functions.
df1 <- bind_cols(data_frame(ids1=paste0("g", 1:10)), as_data_frame(matrix(1:40, 10, 4, dimnames=list(1:10, paste0("CA", 1:4)))))
df1
## # A tibble: 10 <U+00D7> 5
## ids1 CA1 CA2 CA3 CA4
## <chr> <int> <int> <int> <int>
## 1 g1 1 11 21 31
## 2 g2 2 12 22 32
## 3 g3 3 13 23 33
## 4 g4 4 14 24 34
## 5 g5 5 15 25 35
## 6 g6 6 16 26 36
## 7 g7 7 17 27 37
## 8 g8 8 18 28 38
## 9 g9 9 19 29 39
## 10 g10 10 20 30 40
df2 <- bind_cols(data_frame(ids2=paste0("g", c(2,5,11,12))), as_data_frame(matrix(1:16, 4, 4, dimnames=list(1:4, paste0("CB", 1:4)))))
df2
## # A tibble: 4 <U+00D7> 5
## ids2 CB1 CB2 CB3 CB4
## <chr> <int> <int> <int> <int>
## 1 g2 1 5 9 13
## 2 g5 2 6 10 14
## 3 g11 3 7 11 15
## 4 g12 4 8 12 16
Inner join
inner_join(df1, df2, by=c("ids1"="ids2"))
## # A tibble: 2 <U+00D7> 9
## ids1 CA1 CA2 CA3 CA4 CB1 CB2 CB3 CB4
## <chr> <int> <int> <int> <int> <int> <int> <int> <int>
## 1 g2 2 12 22 32 1 5 9 13
## 2 g5 5 15 25 35 2 6 10 14
Left join
left_join(df1, df2, by=c("ids1"="ids2"))
## # A tibble: 10 <U+00D7> 9
## ids1 CA1 CA2 CA3 CA4 CB1 CB2 CB3 CB4
## <chr> <int> <int> <int> <int> <int> <int> <int> <int>
## 1 g1 1 11 21 31 NA NA NA NA
## 2 g2 2 12 22 32 1 5 9 13
## 3 g3 3 13 23 33 NA NA NA NA
## 4 g4 4 14 24 34 NA NA NA NA
## 5 g5 5 15 25 35 2 6 10 14
## 6 g6 6 16 26 36 NA NA NA NA
## 7 g7 7 17 27 37 NA NA NA NA
## 8 g8 8 18 28 38 NA NA NA NA
## 9 g9 9 19 29 39 NA NA NA NA
## 10 g10 10 20 30 40 NA NA NA NA
Right join
right_join(df1, df2, by=c("ids1"="ids2"))
## # A tibble: 4 <U+00D7> 9
## ids1 CA1 CA2 CA3 CA4 CB1 CB2 CB3 CB4
## <chr> <int> <int> <int> <int> <int> <int> <int> <int>
## 1 g2 2 12 22 32 1 5 9 13
## 2 g5 5 15 25 35 2 6 10 14
## 3 g11 NA NA NA NA 3 7 11 15
## 4 g12 NA NA NA NA 4 8 12 16
Full join
full_join(df1, df2, by=c("ids1"="ids2"))
## # A tibble: 12 <U+00D7> 9
## ids1 CA1 CA2 CA3 CA4 CB1 CB2 CB3 CB4
## <chr> <int> <int> <int> <int> <int> <int> <int> <int>
## 1 g1 1 11 21 31 NA NA NA NA
## 2 g2 2 12 22 32 1 5 9 13
## 3 g3 3 13 23 33 NA NA NA NA
## 4 g4 4 14 24 34 NA NA NA NA
## 5 g5 5 15 25 35 2 6 10 14
## 6 g6 6 16 26 36 NA NA NA NA
## 7 g7 7 17 27 37 NA NA NA NA
## 8 g8 8 18 28 38 NA NA NA NA
## 9 g9 9 19 29 39 NA NA NA NA
## 10 g10 10 20 30 40 NA NA NA NA
## 11 g11 NA NA NA NA 3 7 11 15
## 12 g12 NA NA NA NA 4 8 12 16
Anti join
anti_join(df1, df2, by=c("ids1"="ids2"))
## # A tibble: 8 <U+00D7> 5
## ids1 CA1 CA2 CA3 CA4
## <chr> <int> <int> <int> <int>
## 1 g10 10 20 30 40
## 2 g9 9 19 29 39
## 3 g8 8 18 28 38
## 4 g7 7 17 27 37
## 5 g6 6 16 26 36
## 6 g4 4 14 24 34
## 7 g3 3 13 23 33
## 8 g1 1 11 21 31
For additional join options users want to cosult the *_join help pages.
Chaining
To simplify chaining of serveral operations, dplyr provides the %>%
operator. where x %>% f(y) turns into f(x, y). This way one can pipe
together multiple operations by writing them from left-to-right or
top-to-bottom. This makes for easy to type and readable code.
Example 1
Series of data manipulations and export
iris_df %>% # Declare data frame to use
select(Sepal.Length:Species) %>% # Select columns
filter(Species=="setosa") %>% # Filter rows by some value
arrange(Sepal.Length) %>% # Sort by some column
mutate(Subtract=Petal.Length - Petal.Width) # Calculate and append
## # A tibble: 50 <U+00D7> 6
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species Subtract
## <dbl> <dbl> <dbl> <dbl> <chr> <dbl>
## 1 4.3 3.0 1.1 0.1 setosa 1.0
## 2 4.4 2.9 1.4 0.2 setosa 1.2
## 3 4.4 3.0 1.3 0.2 setosa 1.1
## 4 4.4 3.2 1.3 0.2 setosa 1.1
## 5 4.5 2.3 1.3 0.3 setosa 1.0
## 6 4.6 3.1 1.5 0.2 setosa 1.3
## 7 4.6 3.4 1.4 0.3 setosa 1.1
## 8 4.6 3.6 1.0 0.2 setosa 0.8
## 9 4.6 3.2 1.4 0.2 setosa 1.2
## 10 4.7 3.2 1.3 0.2 setosa 1.1
## # ... with 40 more rows
# write_tsv("iris.txt") # Export to file, omitted here to show result
Example 2
Series of summary calculations for grouped data (group_by)
iris_df %>% # Declare data frame to use
group_by(Species) %>% # Group by species
summarize(Mean_Sepal.Length=mean(Sepal.Length),
Max_Sepal.Length=max(Sepal.Length),
Min_Sepal.Length=min(Sepal.Length),
SD_Sepal.Length=sd(Sepal.Length),
Total=n())
## # A tibble: 3 <U+00D7> 6
## Species Mean_Sepal.Length Max_Sepal.Length Min_Sepal.Length SD_Sepal.Length Total
## <chr> <dbl> <dbl> <dbl> <dbl> <int>
## 1 setosa 5.006 5.8 4.3 0.3524897 50
## 2 versicolor 5.936 7.0 4.9 0.5161711 50
## 3 virginica 6.588 7.9 4.9 0.6358796 50
Example 3
Combining dplyr chaining with ggplot
iris_df %>%
group_by(Species) %>%
summarize_all(mean) %>%
reshape2::melt(id.vars=c("Species"), variable.name = "Samples", value.name="Values") %>%
ggplot(aes(Samples, Values, fill = Species)) +
geom_bar(position="dodge", stat="identity")